Os pesquisadores chineses de IA alcançaram o que muitos pensaram estar anos-luz de distância: um modelo de IA de código aberto gratuito que pode corresponder ou exceder o desempenho dos sistemas de raciocínio mais avançados do OpenAI. O que torna isso ainda mais notável foi como eles fizeram: permitindo que a IA se ensine por tentativa e erro, semelhante à maneira como os humanos aprendem.
“Deepseek-r1-zero, um modelo treinado por meio de aprendizado de reforço em larga escala (RL) sem ajuste fino supervisionado (SFT) como uma etapa preliminar, demonstra recursos notáveis de raciocínio”. o Trabalho de pesquisa lê.
“Aprendizagem de reforço” é um método no qual um modelo é recompensado por tomar boas decisões e punido por fazer mal, sem saber qual é qual. Após uma série de decisões, ele aprende a seguir um caminho que foi reforçado por esses resultados.
Inicialmente, durante o Tuneamento fino supervisionado Fase, um grupo de humanos diz ao modelo a saída desejada que eles desejam, dando -lhe contexto para saber o que é bom e o que não é. Isso leva à próxima fase, o aprendizado de reforço, no qual um modelo fornece saídas diferentes e os humanos classificam os melhores. O processo é repetido repetidamente até que o modelo saiba como fornecer consistentemente resultados satisfatórios.
Imagem: Deepseek
O Deepseek R1 é uma direção no desenvolvimento da IA, porque os humanos têm uma parte mínima no treinamento. Ao contrário de outros modelos treinados em vastas quantidades de dados supervisionados, o Deepseek R1 aprende principalmente por meio de aprendizado de reforço mecânico – descobrindo essencialmente as coisas experimentando e obtendo feedback sobre o que funciona.
“Através da RL, o Deepseek-R1-zero surge naturalmente com numerosos comportamentos de raciocínio poderosos e interessantes”, disseram os pesquisadores em seu artigo. O modelo até desenvolveu recursos sofisticados, como auto-verificação e reflexão, sem ser explicitamente programado para fazê-lo.
À medida que o modelo passou por seu processo de treinamento, ele naturalmente aprendeu a alocar mais “tempo de pensamento” para problemas complexos e desenvolveu a capacidade de pegar seus próprios erros. Os pesquisadores destacaram um “A-Ha Moment” Onde o modelo aprendeu a reavaliar suas abordagens iniciais de problemas – algo que não foi explicitamente programado para fazer.
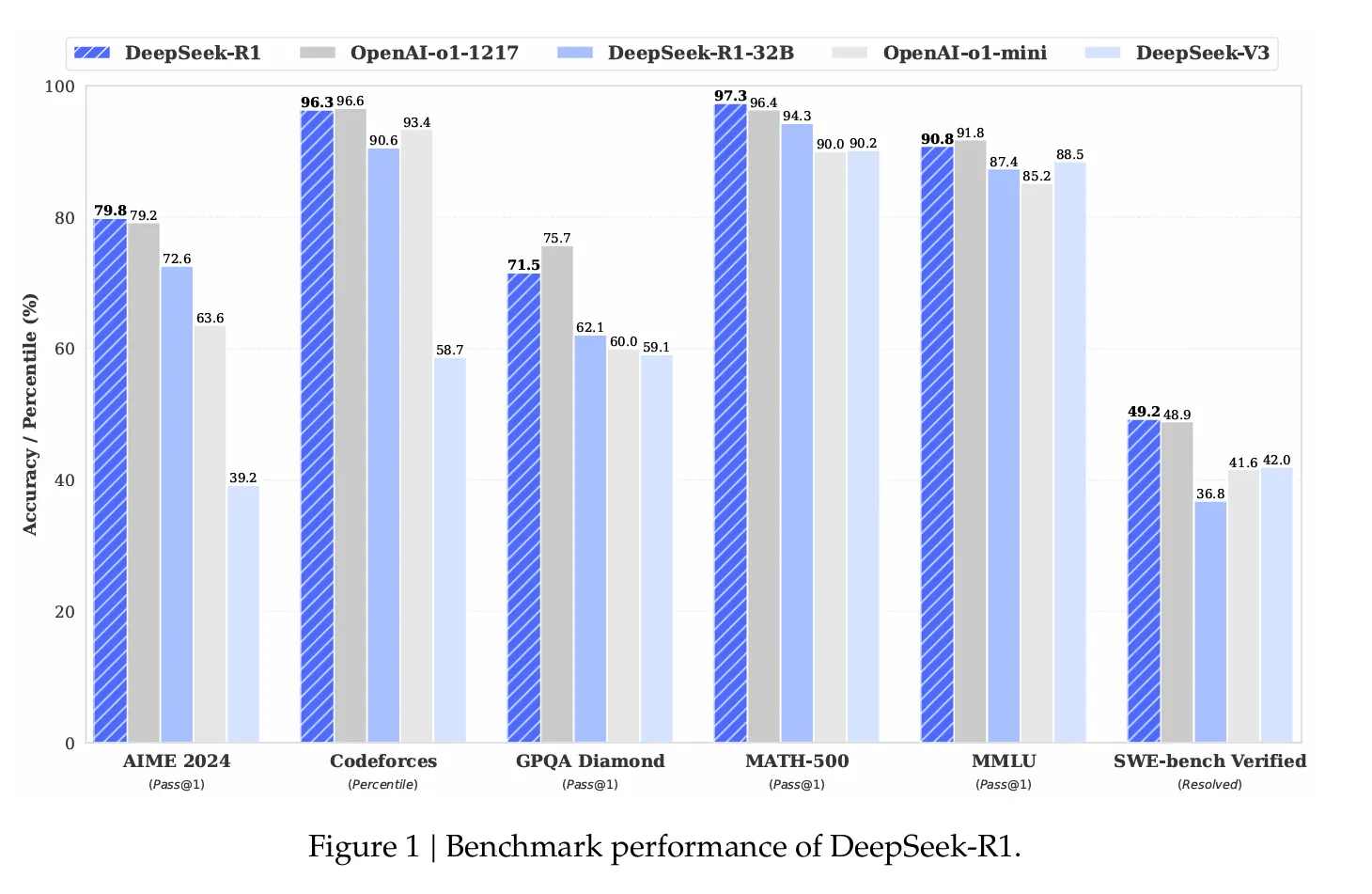
Os números de desempenho são impressionantes. Na referência de matemática Aime 2024, a Deepseek R1 alcançou uma taxa de sucesso de 79,8%, superando o modelo de raciocínio da O1 Open. Nos testes de codificação padronizados, demonstrou desempenho de “nível de especialista”, alcançando uma classificação de 2.029 ELO nas forças de código e superando 96,3% dos concorrentes humanos.
Imagem: Deepseek
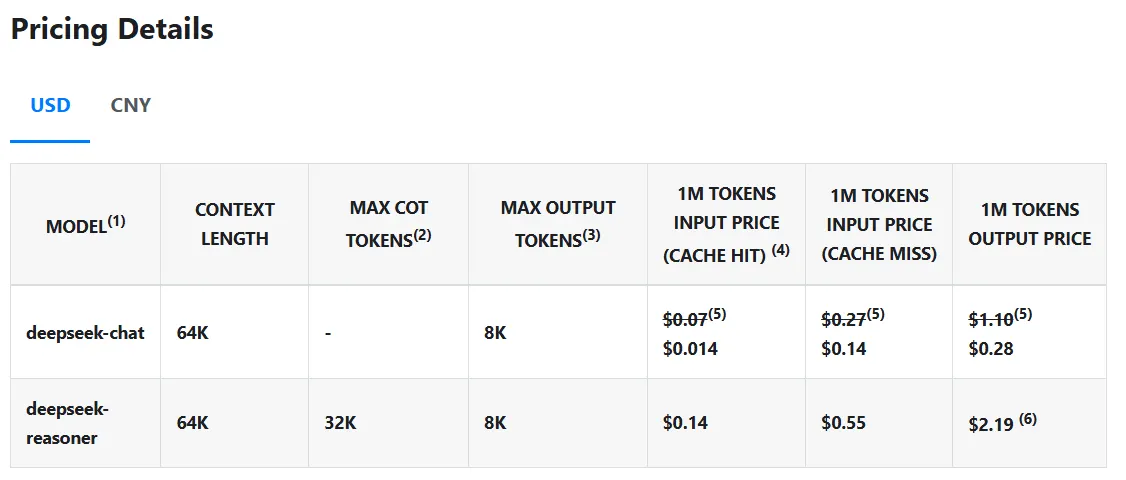
Mas o que realmente diferencia o Deepseek R1 é o seu custo – ou a falta dele. O modelo executa consultas em apenas US $ 0,14 por milhão de tokens comparado com Openai de US $ 7,50tornando -o 98% mais barato. E, diferentemente dos modelos proprietários, os métodos de código e treinamento da DeepSeek R1 são completamente de código aberto sob a licença do MIT, o que significa que qualquer pessoa pode pegar o modelo, usá -lo e modificá -lo sem restrições.
Imagem: Deepseek
Os líderes da IA reagem
O lançamento do Deepseek R1 desencadeou uma avalanche de respostas dos líderes da indústria de IA, com muitos destacando o significado de um modelo totalmente aberto que corresponde líderes proprietários em recursos de raciocínio.
O principal pesquisador da NVIDIA, Dr. Jim Fan, entregou talvez o comentário mais pontual, desenhando um paralelo direto à missão original do Openai. “Estamos vivendo em uma linha do tempo em que uma empresa fora dos EUA mantém a missão original do OpenAI viva-pesquisas de fronteira totalmente abertas que capacitam tudo”, observou Fan, elogiando a transparência sem precedentes de Deepseek.
Estamos vivendo em uma linha do tempo em que uma empresa fora dos EUA mantém a missão original do OpenAI viva – pesquisas verdadeiramente abertas e de fronteira que capacitam tudo. Não faz sentido. O resultado mais divertido é o mais provável.
Os fãs chamaram o significado da abordagem de aprendizado de reforço de DeepSeek: “Eles talvez sejam o primeiro projeto (software de código aberto) que mostra o grande crescimento sustentado do volante (aprendizado de reforço). Ele também elogiou o compartilhamento direto de Deepseek de” algoritmos brutos e curvas de aprendizado de matplotlib “Versus os anúncios orientados por hype mais comuns no setor.
O pesquisador da Apple Awni Hannun mencionou que as pessoas podem executar uma versão quantizada do modelo localmente em seus Macs.
Deepseek R1 671B rodando em 2 m2 ultras mais rápido que a velocidade de leitura.
Chegando-se perto do O1 O1, em casa, em hardware de consumo.
Tradicionalmente, os dispositivos Apple têm sido fracos na IA devido à falta de compatibilidade com o software CUDA da NVIDIA, mas isso parece estar mudando. Por exemplo, o pesquisador da IA, Alex Cheema, foi capaz de executar o modelo completo depois de aproveitar o poder de 8 unidades Apple Mac Mini em execução juntas – o que ainda é mais barato do que os servidores necessários para executar os modelos de IA mais poderosos atualmente disponíveis.
Dito isto, os usuários podem executar versões mais leves do DeepSeek R1 em seus Macs com bons níveis de precisão e eficiência.
No entanto, as reações mais interessantes ocorreram depois de refletir sobre o quão perto a indústria de código aberto é dos modelos proprietários, e o impacto potencial que esse desenvolvimento pode ter para o OpenAI como líder no campo dos modelos de IA de raciocínio.
O fundador da AI da estabilidade, Emad Mostaque, adotou uma postura provocativa, sugerindo que a liberação pressiona os concorrentes mais bem financiados: “Você pode imaginar ser um laboratório de fronteira que é levantado como um bilhão de dólares e agora você não pode liberar seu modelo mais recente porque não pode vencer Deepseek? “
Você pode imaginar ser um laboratório “frontier” que é levantado como um bilhão de dólares e agora não pode lançar seu modelo mais recente porque não pode vencer o Deepseek? 🐳
Seguindo o mesmo raciocínio, mas com uma argumentação mais séria, o empresário de tecnologia Arnaud Bertrand explicou que o surgimento de um modelo competitivo de código aberto pode ser potencialmente prejudicial ao OpenAI, pois isso torna seus modelos menos atraentes para usuários de energia que, de outra forma, poderiam estar dispostos a gastar um muito dinheiro por tarefa.
“É essencialmente como se alguém tivesse lançado um celular a par do iPhone, mas o estava vendendo por US $ 30 em vez de US $ 1000. É tão dramático. ”
A maioria das pessoas provavelmente não percebe o quão ruins é o Deepseek da China para o Openai.
Eles criaram um modelo que corresponde e até excede o mais recente modelo O1 da OpenAI em vários benchmarks, e estão cobrando apenas 3% do preço.
O CEO da Perplexity AI, Arvind Srinivas, enquadrou a liberação em termos de impacto no mercado: “Deepseek replicou amplamente o O1 Mini e o aberto”. Em uma observação de acompanhamento, ele observou o rápido ritmo de progresso: “É meio selvagem ver o raciocínio ser comoditizado tão rápido”.
É meio selvagem ver o raciocínio ser comoditizado tão rápido. Deveríamos esperar totalmente um modelo de nível O3 que seja aberto até o final do ano, provavelmente até meados do ano. pic.twitter.com/oyixks4udm
Srinivas disse que sua equipe trabalhará para trazer as capacidades de raciocínio da DeepSeek R1 ao Perplexity Pro no futuro.
Quick Hands-On
Fizemos alguns testes rápidos para comparar o modelo com o OpenAi O1, começando com uma pergunta bem conhecida para esses tipos de benchmarks: “Quantos Rs estão na palavra Strawberry?”
Normalmente, os modelos lutam para fornecer a resposta correta porque não trabalham com palavras – eles trabalham com tokens, representações digitais de conceitos.
O GPT-4O falhou, o Openai O1 foi bem-sucedido-e o Deepseek R1 também.
No entanto, o O1 foi muito conciso no processo de raciocínio, enquanto o DeepSeek aplicou uma forte saída de raciocínio. Curiosamente, a resposta de Deepseek parecia mais humana. Durante o processo de raciocínio, o modelo parecia falar sozinho, usando gírias e palavras incomuns em máquinas, mas mais amplamente usadas pelos seres humanos.
Por exemplo, ao refletir sobre o número de Rs, o modelo disse a si mesmo: “Ok, deixe -me descobrir (isso)”. Ele também usou “hmmm”, enquanto debatia, e até disse coisas como “Espere, não. Espere, vamos quebrá -lo. ”
O modelo acabou alcançando os resultados corretos, mas gastou muito tempo raciocinando e cuspindo tokens. Sob condições típicas de preços, isso seria uma desvantagem; Mas, dado o estado atual das coisas, ele pode gerar muito mais tokens do que o OpenAi O1 e ainda ser competitivo.
Outro teste para ver como os modelos eram bons no raciocínio foi jogar “espiões” e identificar os autores em uma história curta. Escolhemos uma amostra do Grande bancada conjunto de dados no github. (A história completa está disponível aqui e envolve uma viagem escolar a uma localização remota e nevada, onde alunos e professores enfrentam uma série de desaparecimentos estranhos e o modelo deve descobrir quem era o perseguidor.)
Ambos os modelos pensaram sobre isso por mais de um minuto. No entanto, o chatgpt caiu antes de resolver o mistério.
Mas o Deepseek deu a resposta correta depois de “pensar” sobre isso por 106 segundos. O processo de pensamento estava correto e o modelo era capaz de se corrigir depois de chegar a conclusões incorretas (mas ainda lógicas o suficiente).
A acessibilidade de versões menores impressionou particularmente os pesquisadores. Para o contexto, um modelo de 1,5b é tão pequeno que você pode executá -lo teoricamente localmente em um smartphone poderoso. E mesmo uma versão quantizada do DeepSeek R1 que Small conseguiu ficar cara a cara contra o GPT-4O e o Claude 3,5 sonetos, de acordo com o Data Scientist do Hugging Face Vaibhav Srivastav.
“Deepseek-R1-Distill-Qwen-1.5b supera o GPT-4O e o Claude-3,5 em objetos de matemática com 28,9% no AIME e 83,9% em matemática.”
Há apenas uma semana, a Skynove da UC Berkeley lançou a Sky T1, um modelo de raciocínio também capaz de competir contra a prévia do OpenAI O1.
Os interessados em executar o modelo localmente podem baixá -lo de Girub ou Abraçando o rosto. Os usuários podem baixá-lo, executá-lo, remover a censura ou adaptá-lo a diferentes áreas de especialização, ajustando-o.
Ou se você quiser experimentar o modelo online, vá para Abraçando o bate -papo Ou Deepseek’s Portal da Webque é uma boa alternativa ao ChatGPT – especialmente porque é gratuito, de código aberto e a única interface AI Chatbot com um modelo construído para o raciocínio, além do ChatGPT.
Editado por Andrew Hayward
Geralmente inteligente Boletim informativo
Uma jornada semanal de IA narrada por Gen, um modelo generativo de IA.

Pingback: Por Que O Final Do SAB 121 é Um Grande Negócio - Criptomedia